Back to Graph
researchactiveJune 2025
Dendrite
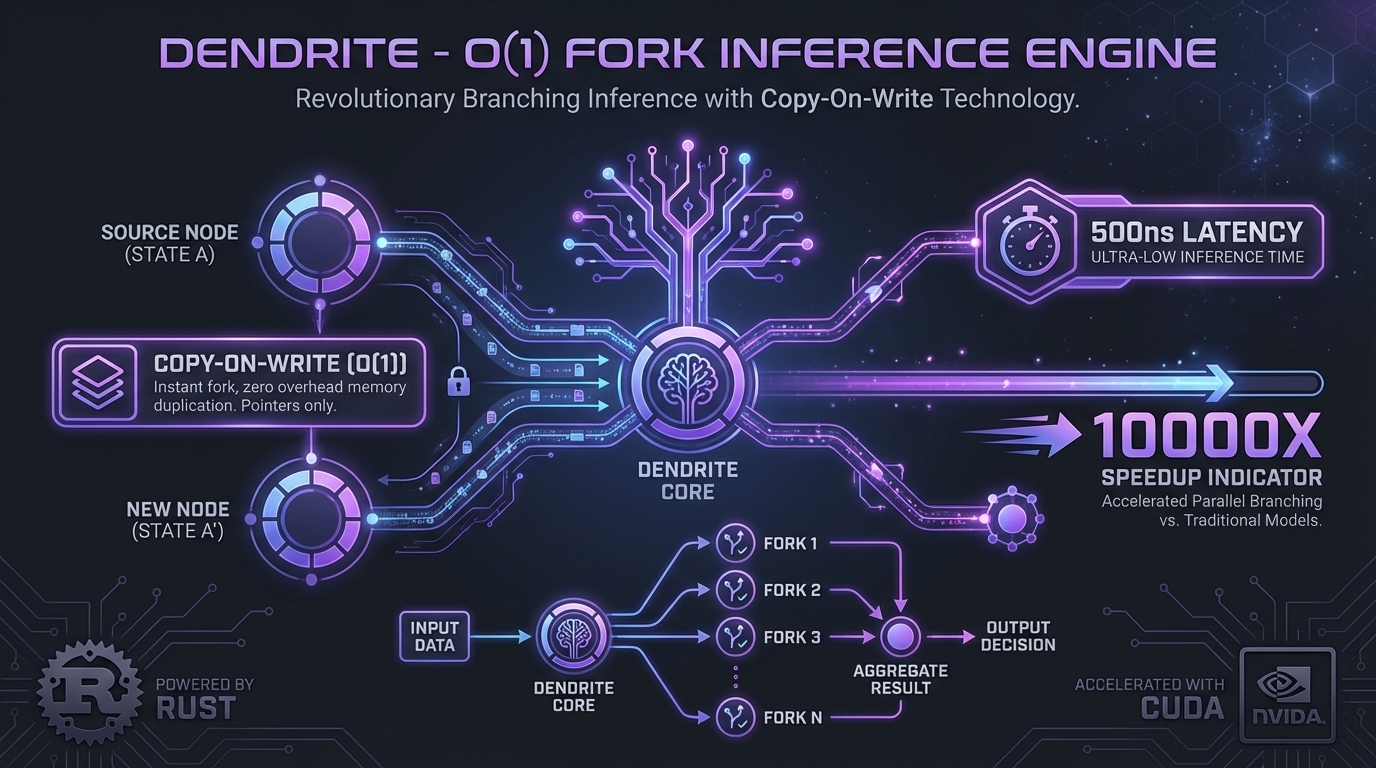
O(1) fork LLM inference engine for tree-structured reasoning
◆ What
O(1) fork LLM inference engine for tree-structured reasoning
500nsfork_latency
10000xspeedup
◆ How
RustCUDAFlashInferCandlePagedAttention
Built on: DGX Spark Platform
◆ Why
Pioneer + The Lab
Hero: Flagship projects with major impact
Overview
Agent-native inference engine with constant-time forking for tree search. 1000-10000x faster branching than vLLM/SGLang using copy-on-write KV cache. Built in Rust with FlashInfer integration. Enables efficient MCTS, beam search, and speculative decoding.
Key Metrics
500ns
fork_latency
10000x
speedup
Technologies
RustCUDAFlashInferCandlePagedAttention